産総研、世界トップレベルの生成AIの開発を開始。東工大やLLM-jpが協力
更新日:2023年10月20日
公開日:2023年10月20日
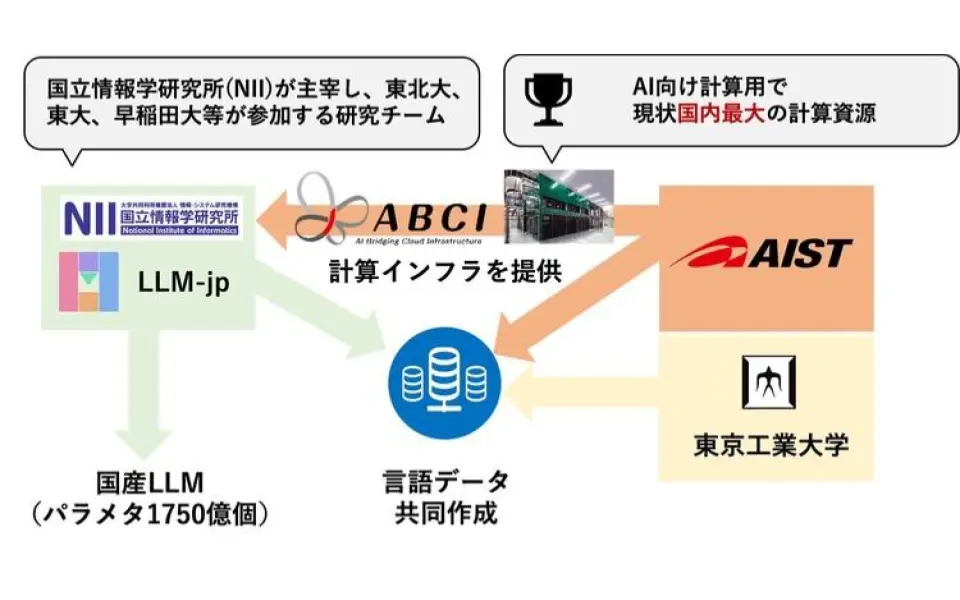
産業技術総合研究所(産総研)は10月17日、同研究所と東京工業大学(東工大)、大学共同利用機関法人情報・システム研究機構の国立情報学研究所(NII)が主宰する「LLM-jp(NII、東北大学、東京大学、早稲田大学などが参画するLLM研究開発チーム)」が、世界トップクラスの生成型AIを支える大規模言語モデル(LLM)を開発すると発表した。
産総研、東工大、およびLLM-jpは、LLM構築におけるデータ、アルゴリズム、計算資源の活用に関するそれぞれの知識を共有し、研究開発を進めていく。日本の産業の競争力を高め、社会的な課題解決に寄与する成果を生み出すことを目指すという。
開発の初期段階として、国産LLMの10倍の大きさである、1750億個のパラメタを備えた大規模言語モデルの開発を開始する。このパラメタ数は、OpenAIが構築したLLM「GPT-3」と同等の規模とのこと。
国産LLMを開発する理由と社会的背景
2022年、OpenAIがChatGPTをリリースしたが、日本以外の企業や研究機関が非公開で行うLLMの開発に頼るだけでは、LLMの構築過程が不透明なまま。ブラックボックス化してしまうため、権利侵害や情報漏えいのリスクがある。
そのため、日本語に適していて、プロセスとデータが明確、信頼性と透明性に富んだ国産LLMの開発が求められている。
参考:産総研の計算資源ABCIを用いて世界トップレベルの生成AIの開発を開始

